Introduction of MapReduce
About MapReduce
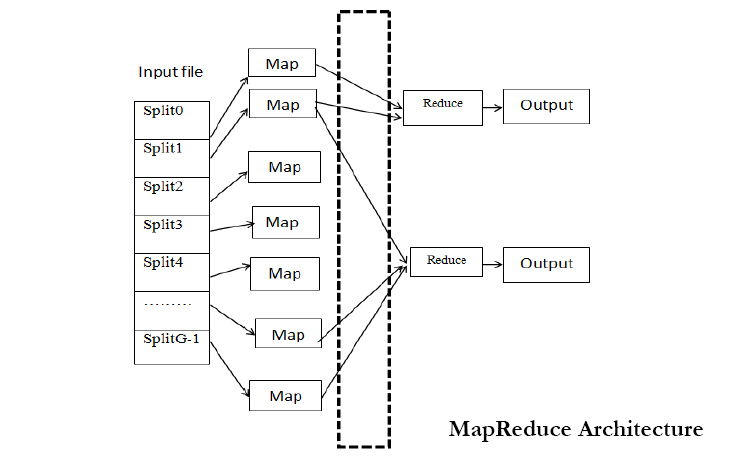
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
Hadoop also provides streaming wherein other langauges could also be used to write MapReduce programs. All data emitted in the flow of a MapReduce program is in the form of <Key,Value> pairs..
The term MapReduce actually refers to two separate and distinct tasks that Hadoop programs perform. The first is the map job, which takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). The reduce job takes the output from a map as input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce job is always performed after the map job.
Hadoop also provides streaming wherein other langauges could also be used to write MapReduce programs. All data emitted in the flow of a MapReduce program is in the form of <Key,Value> pairs..
The term MapReduce actually refers to two separate and distinct tasks that Hadoop programs perform. The first is the map job, which takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). The reduce job takes the output from a map as input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce job is always performed after the map job.
Detail One
Abstract-- Hadoop is a free java based programming framework that supports the processing of large datasets in a distributed computing environment. Mapreduce technique is being used in hadoop for processing and generating large datasets with a parallel distributed algorithm on a cluster. A key benefit of mapreduce is that it automatically handles failures and hides the complexity of fault tolerance from the user. Hadoop uses FIFO (FIRST IN FIRST OUT) scheduling algorithm as default in which the jobs are executed in the order of their arrival. This method suits well for homogeneous cloud and results in poor performance on heterogeneous cloud. Later the LATE (Longest Approximate Time to End) algorithm has been developed which reduces the FIFO's response time by a factor of 2.It gives better performance in heterogenous environment. LATE algorithm is based on three principles i) prioritising tasks to speculate ii) selecting fast nodes to run on iii)capping speculative tasks to prevent thrashing. It takes action on appropriate slow tasks and it could not compute the remaining time for tasks correctly and can't find the real slow tasks. Finally a SAMR (Self Adaptive MapReduce) scheduling algorithm is being introduced which can find slow tasks dynamically by using the historical information recorded on each node to tune parameters. SAMR reduces the execution time by 25% when compared with FIFO and 14% when compared with LATE.
An example of MapReduce (Source from IBM)Let’s look at a simple example. Assume you have five files, and each file contains two columns (a key and a value in Hadoop terms) that represent a city and the corresponding temperature recorded in that city for the various measurement days. Of course we’ve made this example very simple so it’s easy to follow. You can imagine that a real application won’t be quite so simple, as it’s likely to contain millions or even billions of rows, and they might not be neatly formatted rows at all; in fact, no matter how big or small the amount of data you need to analyze, the key principles we’re covering here remain the same. Either way, in this example, city is the key and tempera¬ture is the value.
Toronto, 20
Whitby, 25
New York, 22
Rome, 32
Toronto, 4
Rome, 33
New York, 18
Out of all the data we have collected, we want to find the maximum tem¬perature for each city across all of the data files (note that each file might have the same city represented multiple times). Using the MapReduce framework, we can break this down into five map tasks, where each mapper works on one of the five files and the mapper task goes through the data and returns the maximum temperature for each city. For example, the results produced from one mapper task for the data above would look like this:
(Toronto, 20) (Whitby, 25) (New York, 22) (Rome, 33)
Let’s assume the other four mapper tasks (working on the other four files not shown here) produced the following intermediate results:
(Toronto, 18) (Whitby, 27) (New York, 32) (Rome, 37)(Toronto, 32) (Whitby, 20) (New York, 33) (Rome, 38)(Toronto, 22) (Whitby, 19) (New York, 20) (Rome, 31)(Toronto, 31) (Whitby, 22) (New York, 19) (Rome, 30)
All five of these output streams would be fed into the reduce tasks, which combine the input results and output a single value for each city, producing a final result set as follows:
(Toronto, 32) (Whitby, 27) (New York, 33) (Rome, 38)
As an analogy, you can think of map and reduce tasks as the way a cen¬sus was conducted in Roman times, where the census bureau would dis¬patch its people to each city in the empire. Each census taker in each city would be tasked to count the number of people in that city and then return their results to the capital city. There, the results from each city would be reduced to a single count (sum of all cities) to determine the overall popula¬tion of the empire. This mapping of people to cities, in parallel, and then com¬bining the results (reducing) is much more efficient than sending a single per¬son to count every person in the empire in a serial fashion.
A MapReduce program consists of the following 3 parts:
The Driver code runs on the client machine and is responsible for building the configuration of the job and submitting it to the Hadoop Cluster. The Driver code will contain the main() method that accepts arguments from the command line.
Some of the common libraries that are included for the Driver class :
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
In most cases, the command line parameters passed to the Driver program are the paths to the directory where containing the input files and the path to the output directory. Both these path locations are from the HDFS. The output location should not be present before running the program as it is created after the execution of the program. If the output location already exists the program will exit with an error.
The next step the Driver program should do is to configure the Job that needs to be submitted to the cluster. To do this we create an object of type JobConf and pass the name of the Driver class. The JobConf class allows you to configure the different properties for the Mapper, Combiner, Partitioner, Reducer, InputFormat and OutputFormat.
Sample Code
public class MyDriver{
public static void main(String[] args) throws Exception {
// Create the JobConf object
JobConf conf = new JobConf(MyDriver.class);
// Set the name of the Job
conf.setJobName(“SampleJobName”);
// Set the output Key type for the Mapper
conf.setMapOutputKeyClass(Text.class);
// Set the output Value type for the Mapper
conf.setMapOutputValueClass(IntWritable.class);
// Set the output Key type for the Reducer
conf.setOutputKeyClass(Text.class);
// Set the output Value type for the Reducer
conf.setOutputValueClass(IntWritable.class);
// Set the Mapper Class
conf.setMapperClass(MyMapper.class);
// Set the Reducer Class
conf.setReducerClass(Reducer.class);
// Set the format of the input that will be provided to the program
conf.setInputFormat(TextInputFormat.class);
// Set the format of the output for the program
conf.setOutputFormat(TextOutputFormat.class);
// Set the location from where the Mapper will read the input
FileInputFormat.setInputPaths(conf, new Path(args[0]));
// Set the location where the Reducer will write the output
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
// Run the job on the cluster
JobClient.runJob(conf);
}
}
An example of MapReduce (Source from IBM)Let’s look at a simple example. Assume you have five files, and each file contains two columns (a key and a value in Hadoop terms) that represent a city and the corresponding temperature recorded in that city for the various measurement days. Of course we’ve made this example very simple so it’s easy to follow. You can imagine that a real application won’t be quite so simple, as it’s likely to contain millions or even billions of rows, and they might not be neatly formatted rows at all; in fact, no matter how big or small the amount of data you need to analyze, the key principles we’re covering here remain the same. Either way, in this example, city is the key and tempera¬ture is the value.
Toronto, 20
Whitby, 25
New York, 22
Rome, 32
Toronto, 4
Rome, 33
New York, 18
Out of all the data we have collected, we want to find the maximum tem¬perature for each city across all of the data files (note that each file might have the same city represented multiple times). Using the MapReduce framework, we can break this down into five map tasks, where each mapper works on one of the five files and the mapper task goes through the data and returns the maximum temperature for each city. For example, the results produced from one mapper task for the data above would look like this:
(Toronto, 20) (Whitby, 25) (New York, 22) (Rome, 33)
Let’s assume the other four mapper tasks (working on the other four files not shown here) produced the following intermediate results:
(Toronto, 18) (Whitby, 27) (New York, 32) (Rome, 37)(Toronto, 32) (Whitby, 20) (New York, 33) (Rome, 38)(Toronto, 22) (Whitby, 19) (New York, 20) (Rome, 31)(Toronto, 31) (Whitby, 22) (New York, 19) (Rome, 30)
All five of these output streams would be fed into the reduce tasks, which combine the input results and output a single value for each city, producing a final result set as follows:
(Toronto, 32) (Whitby, 27) (New York, 33) (Rome, 38)
As an analogy, you can think of map and reduce tasks as the way a cen¬sus was conducted in Roman times, where the census bureau would dis¬patch its people to each city in the empire. Each census taker in each city would be tasked to count the number of people in that city and then return their results to the capital city. There, the results from each city would be reduced to a single count (sum of all cities) to determine the overall popula¬tion of the empire. This mapping of people to cities, in parallel, and then com¬bining the results (reducing) is much more efficient than sending a single per¬son to count every person in the empire in a serial fashion.
A MapReduce program consists of the following 3 parts:
- Driver
- Mapper
- Reducer
The Driver code runs on the client machine and is responsible for building the configuration of the job and submitting it to the Hadoop Cluster. The Driver code will contain the main() method that accepts arguments from the command line.
Some of the common libraries that are included for the Driver class :
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
In most cases, the command line parameters passed to the Driver program are the paths to the directory where containing the input files and the path to the output directory. Both these path locations are from the HDFS. The output location should not be present before running the program as it is created after the execution of the program. If the output location already exists the program will exit with an error.
The next step the Driver program should do is to configure the Job that needs to be submitted to the cluster. To do this we create an object of type JobConf and pass the name of the Driver class. The JobConf class allows you to configure the different properties for the Mapper, Combiner, Partitioner, Reducer, InputFormat and OutputFormat.
Sample Code
public class MyDriver{
public static void main(String[] args) throws Exception {
// Create the JobConf object
JobConf conf = new JobConf(MyDriver.class);
// Set the name of the Job
conf.setJobName(“SampleJobName”);
// Set the output Key type for the Mapper
conf.setMapOutputKeyClass(Text.class);
// Set the output Value type for the Mapper
conf.setMapOutputValueClass(IntWritable.class);
// Set the output Key type for the Reducer
conf.setOutputKeyClass(Text.class);
// Set the output Value type for the Reducer
conf.setOutputValueClass(IntWritable.class);
// Set the Mapper Class
conf.setMapperClass(MyMapper.class);
// Set the Reducer Class
conf.setReducerClass(Reducer.class);
// Set the format of the input that will be provided to the program
conf.setInputFormat(TextInputFormat.class);
// Set the format of the output for the program
conf.setOutputFormat(TextOutputFormat.class);
// Set the location from where the Mapper will read the input
FileInputFormat.setInputPaths(conf, new Path(args[0]));
// Set the location where the Reducer will write the output
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
// Run the job on the cluster
JobClient.runJob(conf);
}
}
